③ 品質レポート
学習が終わると通常複数のチェックポイントが残ります。その中で どの時点が最も良いか は loss の数値だけでは判断が難しく、結局は耳で聴いて確かめる必要があります。
品質レポートは複数のチェックポイントで同じ文を合成して 1枚の HTML ファイル にまとめてくれます。ブラウザで横に並べて聴きながら最も良い時点を選べます。
実行
学習完了後に CLI を実行し、メインメニューで 品質レポート を選択します。
uv run poe cli学習が完了したデータセット(exports/<model_name>/*.safetensors があるもの)のみがリストアップされます。前処理のみ実行された状態では表示されません。
話者を選ぶと CLI がチェックポイント一覧を出力し、評価テキストプリセットを尋ねます。
? 話者選択 つくよみ
チェックポイント 5個使用
· hayakoe_つくよみ_e15_s500
· hayakoe_つくよみ_e30_s1000
· hayakoe_つくよみ_e45_s1500
· hayakoe_つくよみ_e59_s2000
· hayakoe_つくよみ_e74_s2500
? テキスト選択
❯ サンプル - 短い (3個)
サンプル - 中程度 (2個)
サンプル - 長い (1個)
サンプル - 全部 (6個)
直接入力
戻る評価テキスト選択
どの文で比較するかプリセットの中から1つを選びます。
- サンプル - 短い (3個)
- 「おはようございます。今日もよろしくお願いします。」
- 「えっ、本当ですか?それはすごいですね!」
- 「静かな夜に、星が綺麗に見えます。」
- サンプル - 中程度 (2個)
- 「先週の土曜日、家族で動物園に行きました。子供たちはパンダを見てとても喜んでいました。天気も良くて、最高の一日になりました。」
- 「音声合成の技術は年々進化しています。最近では人間の声と区別がつかないほど自然な音声を生成できるようになりました。今後の発展が楽しみです。」
- サンプル - 長い (1個)
- 「春が来ると、日本中で桜が咲き始めます。人々は公園や川沿いに集まって、お花見を楽しみます。友人や家族と一緒にお弁当を広げ、美しい花びらが舞い散る様子を眺めるのは、日本の春の風物詩です。桜の季節は短く、わずか一週間ほどで散ってしまいますが、その儚さがまた人々の心を惹きつけるのかもしれません。」
- サンプル - 全部 (6個) — 上記3つをまとめて
- 直接入力 — 好きな文を直接入力(空行で終了)
成果物
<dataset>/reports/report_<YYYYMMDD_HHMMSS>.html に HTML 1枚が生成されます。WSL2 ではデフォルトブラウザで開く機能を提供します。
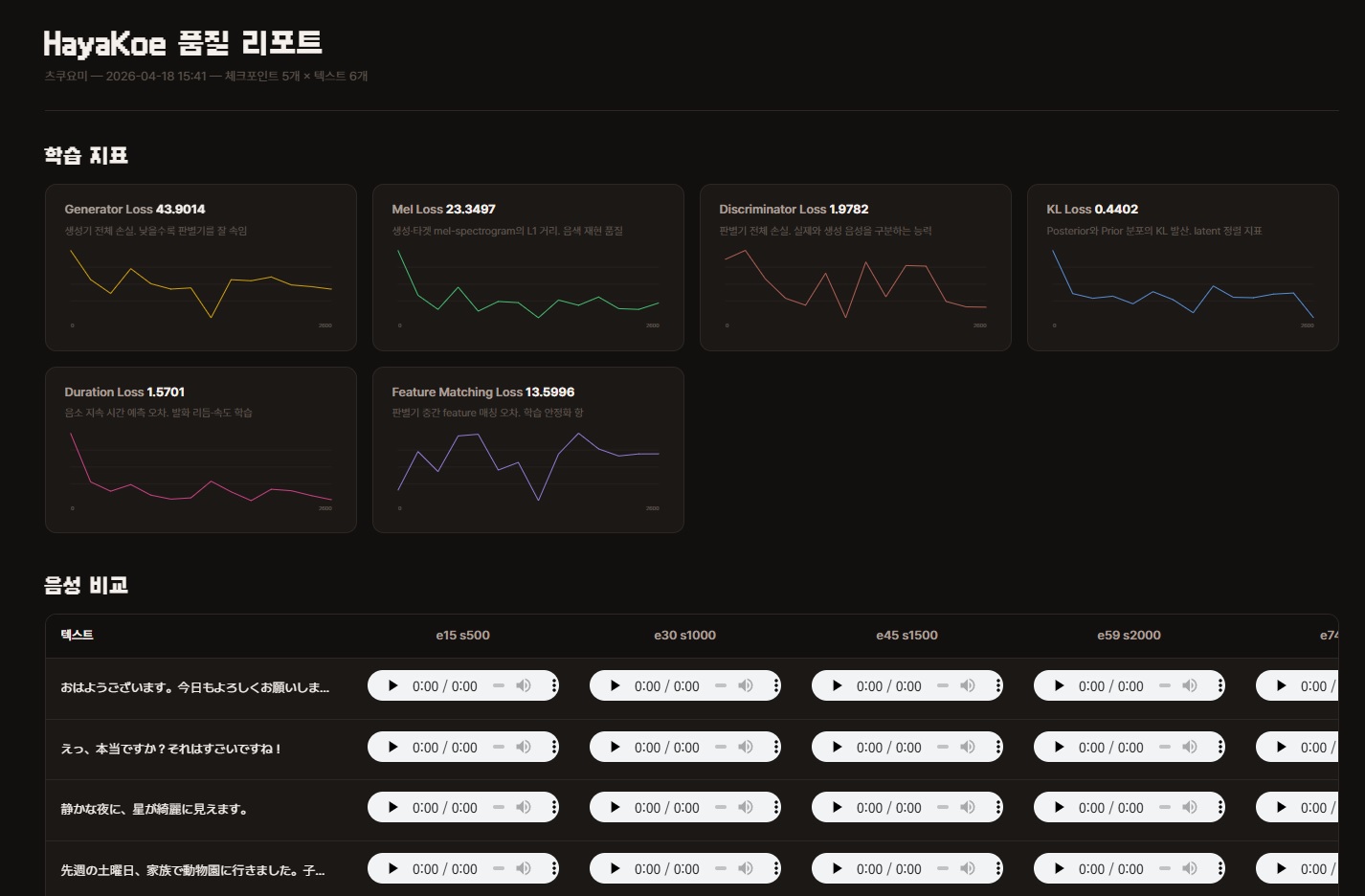
HTML の中には2つのものが含まれています。
- 学習指標チャート6種 — loss 変化グラフ。チェックポイント選択の参考にはなりますが、最終決定は耳で行います。
- オーディオ比較表 — 行は評価文、列はチェックポイント。各セルの
<audio>プレイヤーを押して直接聴きます。
共有が簡単です
WAV が HTML 内に base64 で埋め込まれているため、ファイル1つを移動するだけですべてのオーディオが一緒について来ます。
Slack・Notion にそのままアップロードしても外部ファイル依存なしに再生されます。
内部動作 — チェックポイントのサンプリングと生成順序
チェックポイントのサンプリング
チェックポイントが8個を超えると自動的に均等サンプリングします(最初・最後 + その間6個)。10個・20個あってもページが横に溢れません。
生成順序
<dataset>/training/と<dataset>/training/eval/から TensorBoard イベントファイルのスカラー指標を収集します。- チェックポイントを1つずつ
hayakoe.tts_model.TTSModelでロードし、評価テキスト全部を合成した後 unload します。VRAM を節約するため一度に1つだけメモリにロードします。 - 指標チャートとオーディオ表を self-contained HTML に組み立てます。
レポートの読み方
レポートを開くとまず 学習指標チャート6個 が表示され、その下に オーディオ比較表 があります。
オーディオ比較表を中心に見てください。loss の数値だけで判断しないでください — 過学習が始まると数値は下がり続けますが、耳で聴く結果はかえって悪くなります。
学習指標チャート6種
各チャート右上の数値は 最終ステップの値 です。曲線自体も重要ですが、まず終点を確認してください。
- Generator Loss — 生成器の全体損失。低いほど判別器をうまく騙せている
- Mel Loss — 生成・ターゲット mel-spectrogram の L1 距離。音色再現品質
- Discriminator Loss — 判別器の全体損失。実際の音声と生成音声を区別する能力
- KL Loss — Posterior と Prior 分布の KL ダイバージェンス。latent アライメント指標
- Duration Loss — 音素持続時間予測の誤差。発話リズム・速度の学習
- Feature Matching Loss — 判別器の中間 feature マッチング誤差。学習安定化項
どのチェックポイントを選ぶか
全部聴いてみて、最も音が良いものを選んでください。
ただし、最後のチェックポイントが必ずしも最良とは限りません。データが少ないと後半になるほどかえって不自然になる場合もあるので、中間のチェックポイントまで必ず一緒に聴いてください。
確信が持てなければ候補を2~3個 ④ デプロイ でそれぞれ異なる名前でアップロードしておき、実際に使いながら選ぶこともできます。
次のステップ
- 選んだチェックポイントをデプロイする:④ デプロイ
- ハイパーパラメータを変えて再学習:② 前処理 & 学習