① データ準備
SBV2 の学習には (wav ファイル, 対応するテキスト) のペアと話者メタデータが必要です。
録音だけからこれを手作業で作るのは時間のかかる作業なので、HayaKoe はこのプロセスをブラウザベースの GUI にまとめてあります。
場所は dev-tools/preprocess/ です。
準備
このステップでは動画からオーディオを抽出するのに FFmpeg を使用します。
ML 依存関係は 全体の流れページの準備 で実行した uv sync にすべて含まれていますが、FFmpeg はシステムパッケージなので別途インストールが必要です。
FFmpeg インストール(Ubuntu / Debian)
sudo apt update
sudo apt install ffmpegインストール完了後にバージョンが表示されるか確認します。
ffmpeg -version実行
前処理ツールの実行
# リポジトリルートで
uv run poe preprocessブラウザで http://localhost:8000 にアクセスするとダッシュボードが表示されます。
実行したら "address already in use" エラーが出る場合
8000番ポートを他のプログラムが既に使っているという意味です。
エラー例は通常このような形です。
ERROR: [Errno 98] error while attempting to bind on address
('0.0.0.0', 8000): address already in use--port オプションで空いている別のポートを指定して再実行してください(例:8123)。
uv run poe preprocess --port 8123この場合、アクセスアドレスも http://localhost:8123 に変わります。
基本ワークフロー
ダッシュボードに初めてアクセスすると以下のような画面が表示されます。
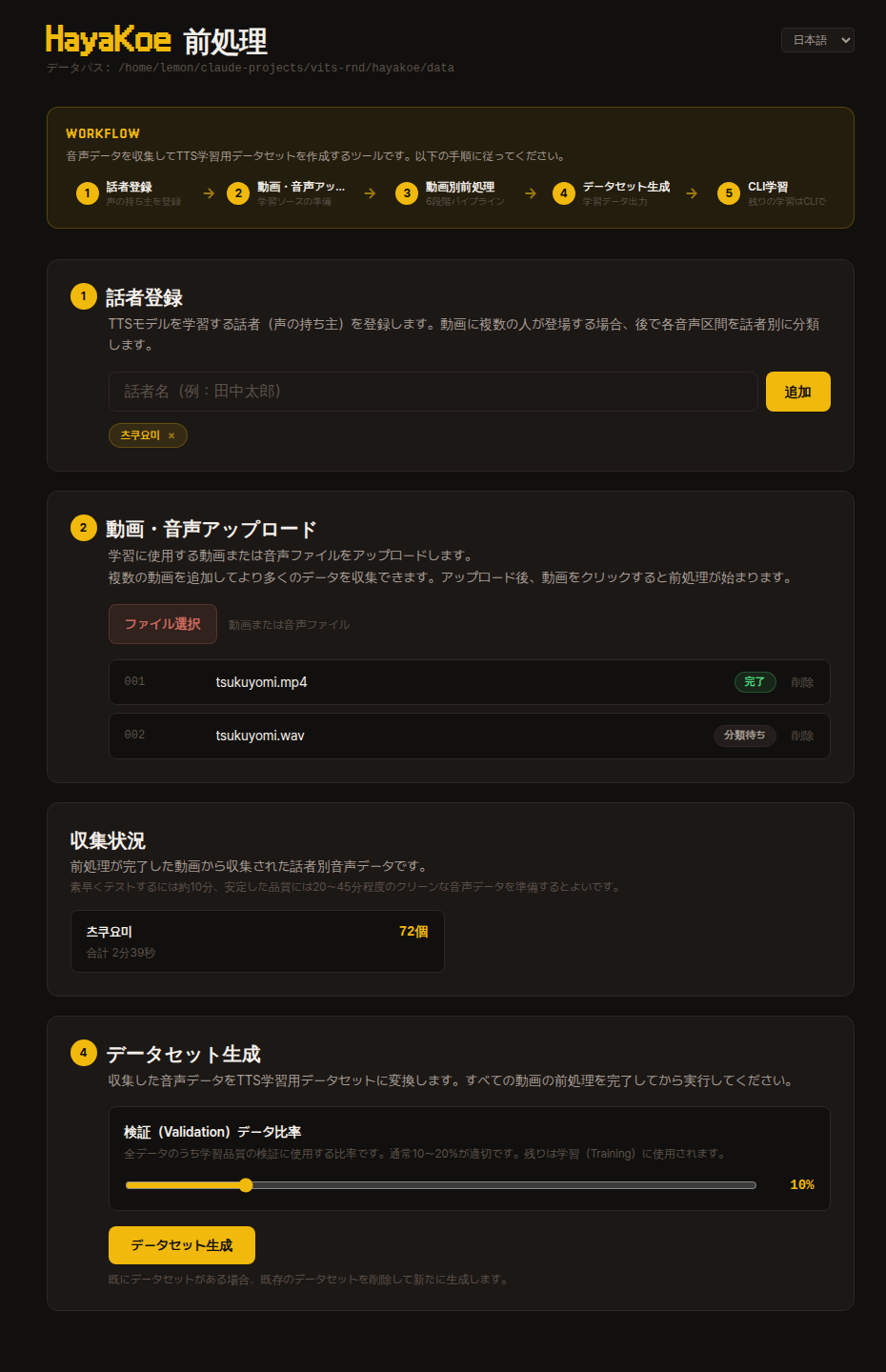
上部の WORKFLOW エリアが全体の流れを一目で見せてくれ、その下に同じステップがカード形式で展開されます。
上から順に辿れば良く、前のステップが終わらないと次のステップカードが有効になりません。
1. 話者登録
学習対象となる話者の名前を登録します。
話者名は自分が識別できる名前なら何でも構いません(例:tsukuyomi)。
2. 動画アップロード
学習ソースとなる動画をアップロードします。
動画だけでなく mp3・wav・flac などのオーディオファイルもそのまま受け付けます — 内部で FFmpeg が同様に処理します。
アップロードが完了すると動画カードがリストに追加され、カードをクリックするとその動画の前処理パイプラインページに移動します。
動画ごとの6ステップパイプライン
動画詳細ページに入ると上部に6ステップのプログレスバーが表示され、下の NEXT STEP カードのボタンで現在のステップを1つずつ実行します。
各ステップが完了すると自動的に「完了」に変わり、次のステップが開きます。
途中で中断して戻ってきても残りのステップから再開できます。
1. 抽出
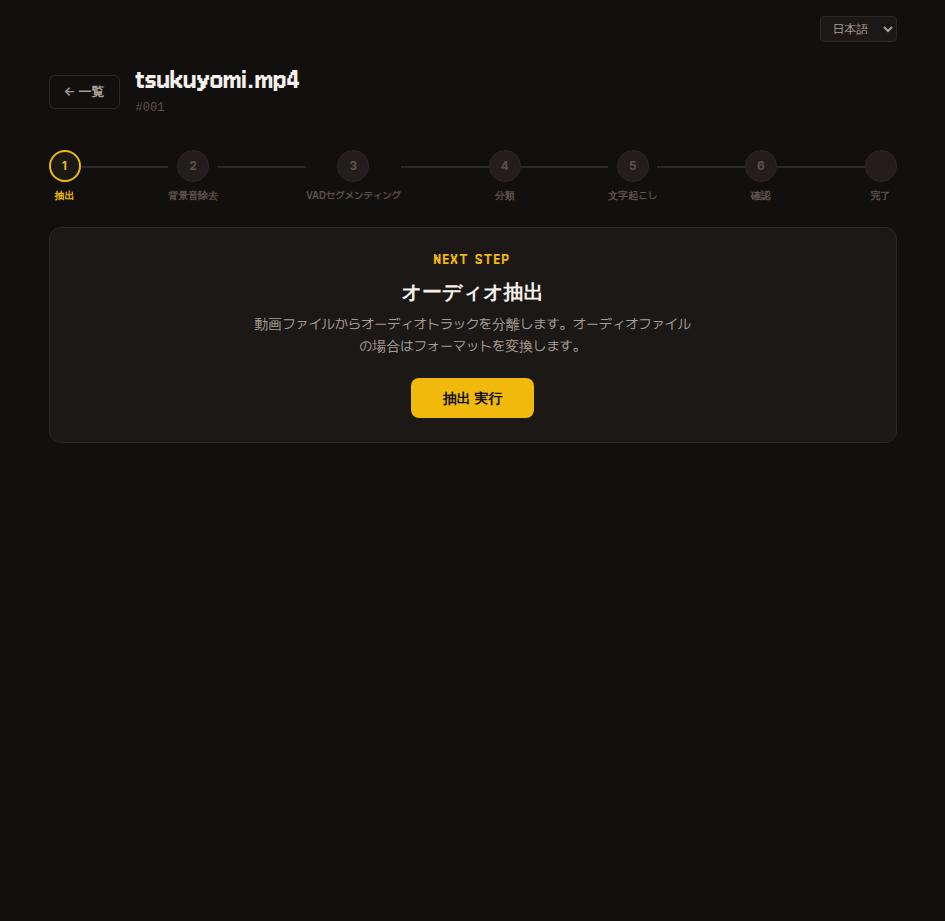
元データから音声のみを抽出して保存します。
抽出が完了したら次のステップに進んでください。
内部動作
内部的に FFmpeg を使って extracted.wav ファイルを抽出します。
アップロードしたファイルが既に mp3・wav・flac などのオーディオファイルであれば、内容はそのままでフォーマットのみ wav に変換します。
2. 背景音除去
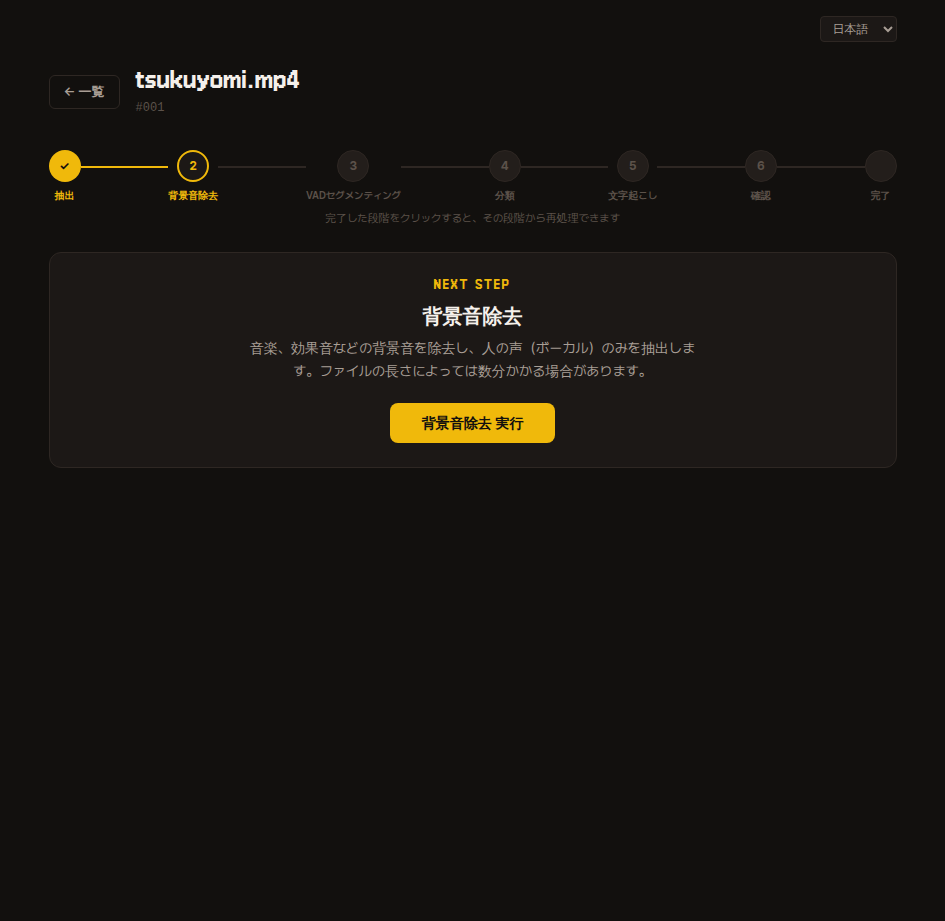
BGM・効果音などの背景音を除去し、人の声だけを残します。
ファイルの長さに比例して数分かかる場合がありますのでお待ちください。
内部動作
audio-separator ライブラリでボーカルのみを分離し vocals.wav に保存します。
3. VAD セグメンティング
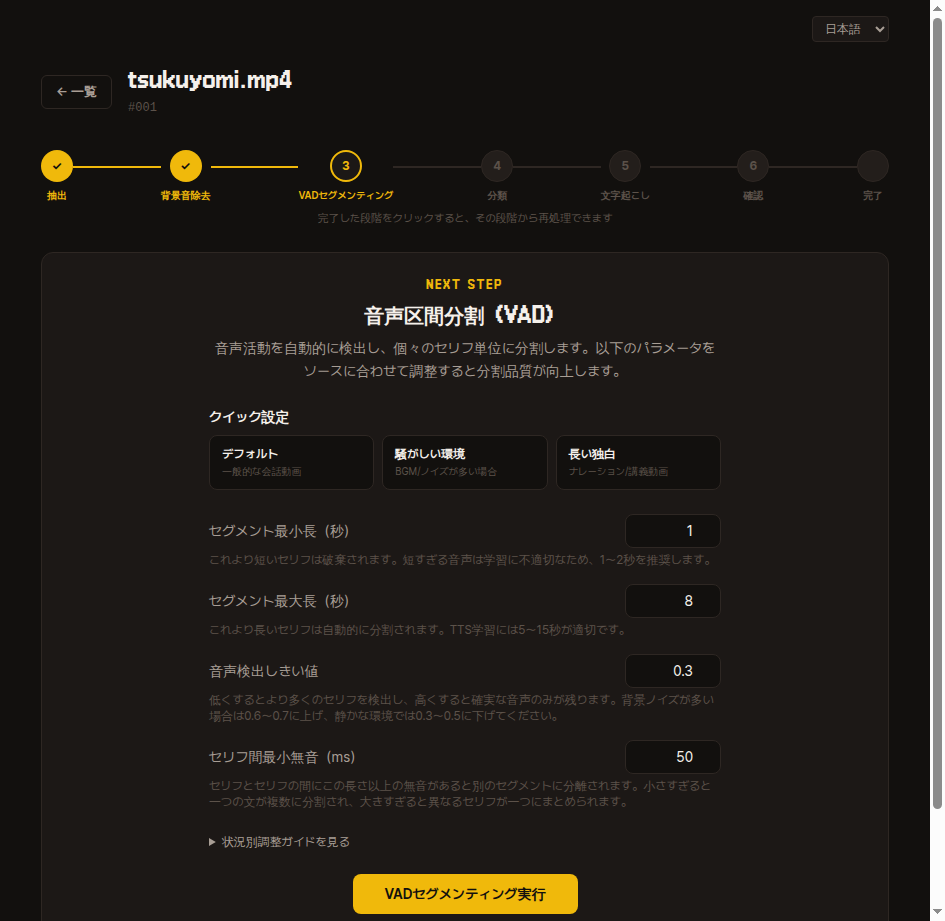
長い録音を無音区間を基準に短い文単位で切り出します。
デフォルト値でまず実行してみて、分割結果が気に入らなければ4つのパラメータを調整して同じ動画から再抽出できます。
- セグメント最小長(秒) — これより短い音声は破棄します。TTS 学習には1-2秒を推奨します。
- セグメント最大長(秒) — これより長いセリフは自動的に分割されます。5-15秒が適切です。
- 音声検出閾値 — まず低い値(0.2~0.3)から始めて、ノイズが多すぎる場合は少しずつ上げる方向を推奨します。
- セリフ間最小無音(ms) — まずデフォルト値から始めてください。複数の話者が連続して話して1つのセグメントに混ざる場合は値を下げ、1つのセリフが短く切れすぎる場合は値を上げる方向でチューニングします。
内部動作
Silero VAD で音声活動区間を検出し、上記パラメータに合わせて切り出した結果を vad.json と segments/unclassified/*.wav に保存します。
再実行すると segments/unclassified/ が上書きされます。
4. 分類
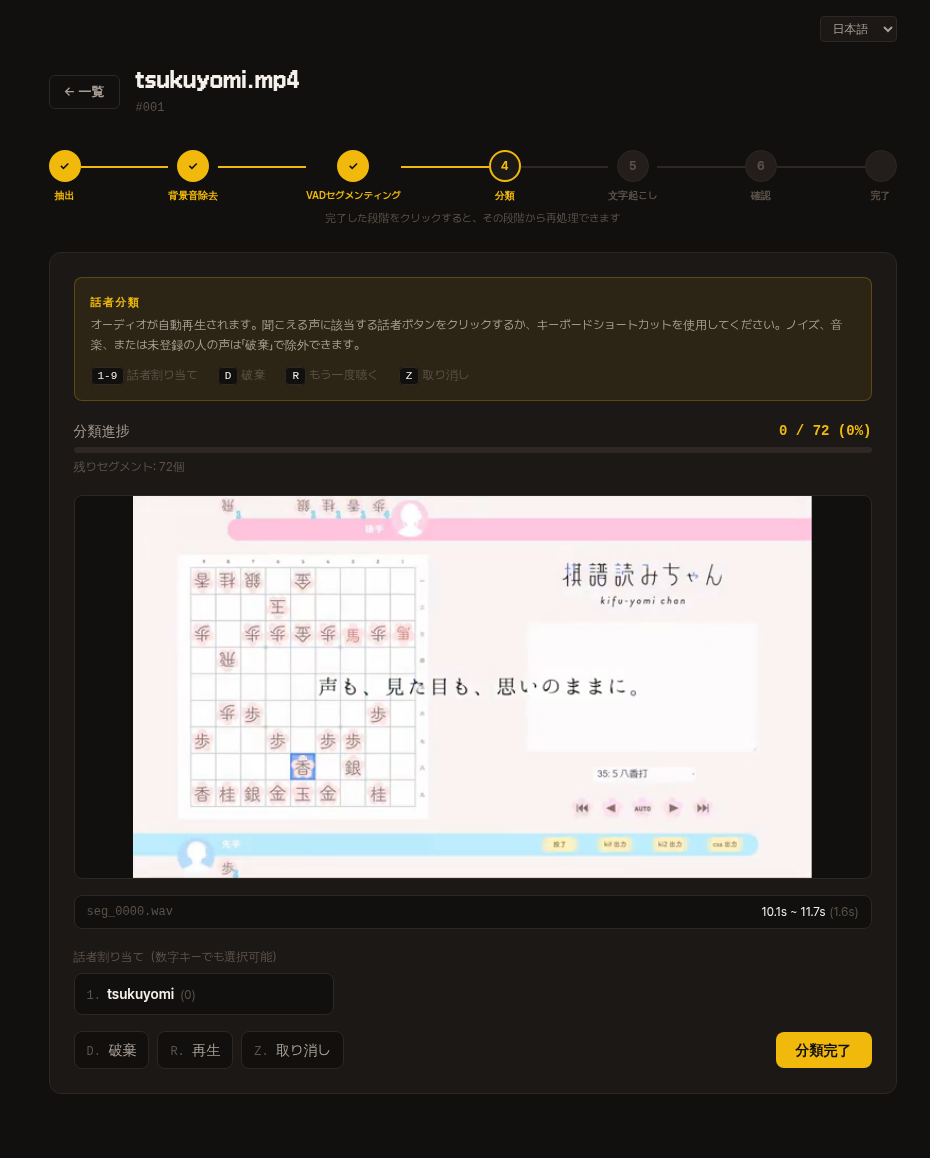
切り出したセグメントが1つずつ自動再生されます。
聞こえる声の話者番号キー(1-9)またはボタンを押して割り当ててください。
ノイズ・音楽・登録していない人の声は 破棄(D) で除外します。
| キー | 動作 |
|---|---|
1-9 | 該当番号の話者に割り当て |
D | 破棄 |
R | もう一度聴く |
Z | 元に戻す |
上部のプログレスバーで残りのセグメント数を確認でき、すべて処理したら 分類完了 ボタンを押して次のステップに進みます。
内部動作
分類結果は segments/<話者>/ の構造で保存されます。
5. 書き起こし
各セグメントの音声を聞いて日本語テキストに自動変換します。
変換結果は次のステップで直接修正できるので、ここでは実行ボタンを押すだけです。
内部動作
Whisper モデルで書き起こした結果を transcription.json に保存します。
6. レビュー
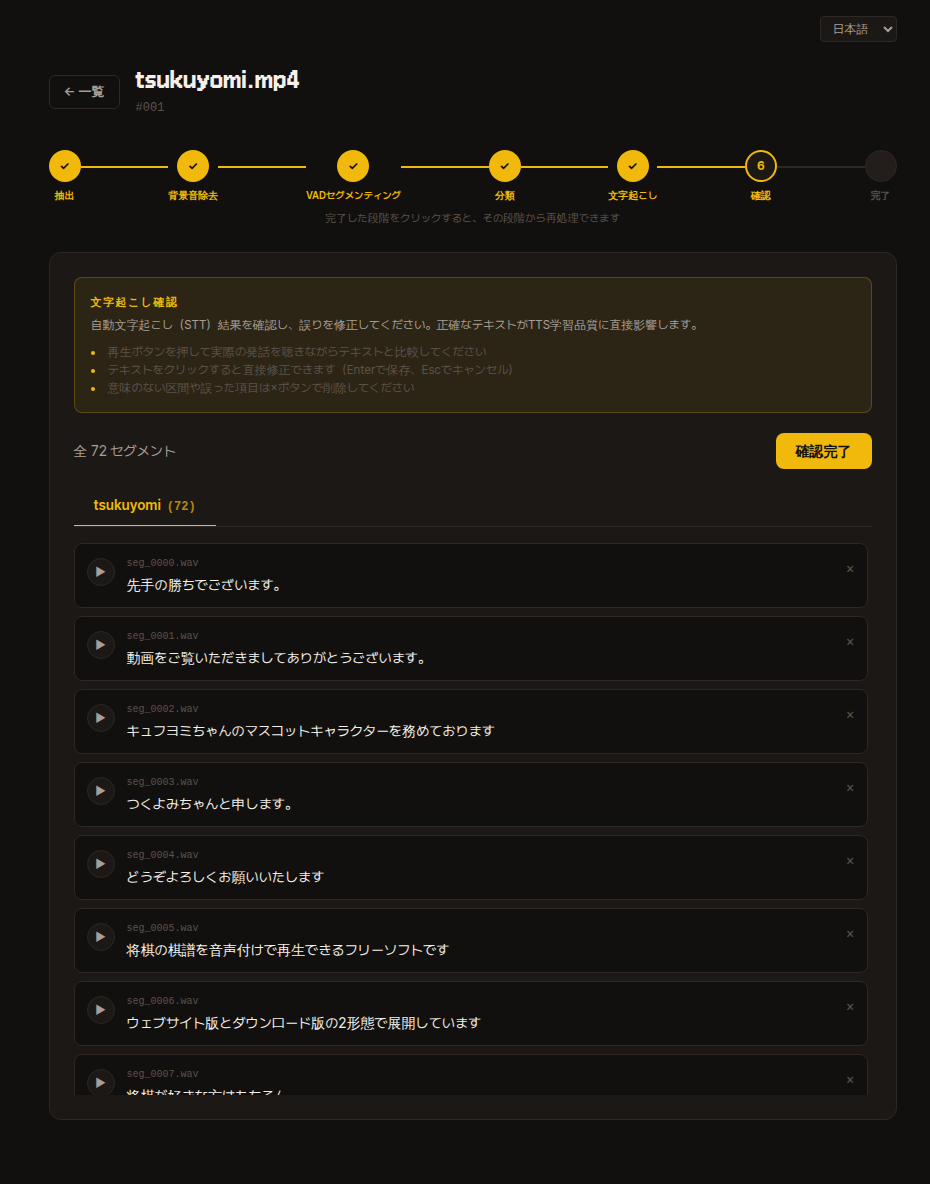
自動書き起こし結果を確認してエラーを修正します。
日本語がわからなければひとまずスキップしても構いません。学習後に品質が低いと感じたらそのときに戻って修正しても良いです。
- 再生ボタン を押して実際の発話を聴きながらテキストと比較します。
- テキストをクリックするとすぐに修正 できます(
Enterで保存、Escでキャンセル)。 - 意味のない区間や誤ったセグメントは
×ボタンで削除します。 - すべて確認したら右上の レビュー完了 ボタンを押して次のステップに進みます。
内部動作
レビュー完了マーカーは review_done.json に保存されます。
複数の動画でデータを集める
1人の話者に対して複数の動画をアップロードできます。
動画ごとに上記の6ステップを繰り返してデータを積み上げるほど学習品質が上がります。処理済みデータ基準で 最低10分、30分以上あれば大抵十分 です。
動画詳細ページ左上の ← 一覧 ボタンでダッシュボードに戻り、次の動画をアップロードしてください。すべての動画のレビューが終わった後、以下のデータセット生成ステップに進みます。
データセット生成
すべての動画のレビューが完了するとダッシュボードで データセット生成 ボタンが有効になります。
val_ratio の値を1つ指定するだけで学習用データセットが自動的に作成されます(デフォルト 0.1)。
val_ratio とは?
全データのうち 学習には使わず、学習がうまくいっているか中間チェックに使う割合 です。
学習に使ったデータだけではモデルがその文だけ暗記して新しい文は不自然に作ってしまう可能性があります。そこで一部のデータを意図的に取っておき、学習途中にそのデータで合成した結果が自然かどうか別途確認します。
デフォルト値 0.1(10%)であればほとんどの場合十分です。
生成されたデータセットは ② 前処理 & 学習 CLI が自動的に認識するため、すぐに次のステップに進めます。
内部動作 — データセット構造とデフォルト設定
生成されるディレクトリ構造:
data/dataset/<speaker>/
├── audio/ # すべての動画のセグメントを一箇所にコピー
│ └── <video_id>_<orig_seg>.wav
├── esd.list # <abspath>|<speaker>|JP|<text>
├── train.list # esd.list の (1 - val_ratio) ランダム分割 (seed 42)
├── val.list # esd.list の val_ratio ランダム分割
└── sbv2_data/
└── config.json # SBV2 JP-Extra デフォルト設定config.json の主なデフォルト値:
model_name: "hayakoe_<speaker>"version: "2.7.0-JP-Extra"train.epochs: 500,batch_size: 2,learning_rate: 0.0001train.eval_interval: 1000,log_interval: 200data.sampling_rate: 44100,num_styles: 7style2id: Neutral / Happy / Sad / Angry / Fear / Surprise / Disgust
これらの値は ② 前処理 & 学習 ステップの 学習設定の編集 で変更できます。
内部動作 — data/ ルート全体構造
--data-dir ./data 基準の最終構造:
data/
├── speakers.json # 登録済み話者リスト
├── videos/ # 動画ごとの前処理作業スペース
│ └── <001, 002, ...>/
│ ├── source.<ext>
│ ├── meta.json
│ ├── extracted.wav
│ ├── vocals.wav
│ ├── vad.json
│ ├── segments/
│ ├── classification.json
│ ├── transcription.json
│ └── review_done.json
└── dataset/ # 学習ステップの入力
└── <speaker>/ # ← CLI がこのパスを自動認識CLI は data/dataset/ 以下で esd.list または sbv2_data/esd.list を持つディレクトリを自動的にリストアップします。
次のステップ
- データセットを学習に渡す:② 前処理 & 学習