③ 品質報告
訓練結束後通常會留下多個檢查點。其中 哪個時間點最好 僅看 loss 數字很難判斷,最終還是要靠耳朵來聽。
品質報告將多個檢查點合成同一句話,彙總到 一張 HTML 檔案 中。在瀏覽器中橫向並排試聽,選擇最佳時間點即可。
執行
訓練結束後啟動 CLI,在主選單中選擇 品質報告。
bash
uv run poe cli只有訓練完成的資料集(exports/<model_name>/*.safetensors 存在的)才會被列出。僅完成前處理的不會顯示。
選擇說話人後 CLI 會輸出檢查點清單並詢問評估文字預設。
text
? 選擇說話人 tsukuyomi
使用 5 個檢查點
· hayakoe_tsukuyomi_e15_s500
· hayakoe_tsukuyomi_e30_s1000
· hayakoe_tsukuyomi_e45_s1500
· hayakoe_tsukuyomi_e59_s2000
· hayakoe_tsukuyomi_e74_s2500
? 選擇文字
❯ 範例 - 短 (3 個)
範例 - 中 (2 個)
範例 - 長 (1 個)
範例 - 全部 (6 個)
手動輸入
返回評估文字選擇
選擇用哪些句子進行比較的預設。
- 範例 - 短 (3 個)
- 「おはようございます。今日もよろしくお願いします。」
早安。今天也請多關照。 - 「えっ、本当ですか?それはすごいですね!」
欸?真的嗎?那好厲害啊! - 「静かな夜に、星が綺麗に見えます。」
在寂靜的夜晚,星星看起來很美。
- 「おはようございます。今日もよろしくお願いします。」
- 範例 - 中 (2 個)
- 「先週の土曜日、家族で動物園に行きました。子供たちはパンダを見てとても喜んでいました。天気も良くて、最高の一日になりました。」
上週六和家人去了動物園。孩子們看到熊貓非常開心。天氣也很好,成了最棒的一天。 - 「音声合成の技術は年々進化しています。最近では人間の声と区別がつかないほど自然な音声を生成できるようになりました。今後の発展が楽しみです。」
語音合成技術每年都在進步。最近已經能生成自然到無法與人聲區分的語音了。期待今後的發展。
- 「先週の土曜日、家族で動物園に行きました。子供たちはパンダを見てとても喜んでいました。天気も良くて、最高の一日になりました。」
- 範例 - 長 (1 個)
- 「春が来ると、日本中で桜が咲き始めます。人々は公園や川沿いに集まって、お花見を楽しみます。友人や家族と一緒にお弁当を広げ、美しい花びらが舞い散る様子を眺めるのは、日本の春の風物詩です。桜の季節は短く、わずか一週間ほどで散ってしまいますが、その儚さがまた人々の心を惹きつけるのかもしれません。」
春天到來時,日本各地的櫻花開始綻放。人們聚集在公園和河畔賞花。和朋友家人一起打開便當,欣賞美麗花瓣紛飛的景象,是日本春天的風物詩。櫻花季節很短,僅一週左右便散落,但或許正是這份短暫更能打動人心。
- 「春が来ると、日本中で桜が咲き始めます。人々は公園や川沿いに集まって、お花見を楽しみます。友人や家族と一緒にお弁当を広げ、美しい花びらが舞い散る様子を眺めるのは、日本の春の風物詩です。桜の季節は短く、わずか一週間ほどで散ってしまいますが、その儚さがまた人々の心を惹きつけるのかもしれません。」
- 範例 - 全部 (6 個) — 以上三者合併
- 手動輸入 — 直接輸入想要的句子(空行結束)
產出
在 <dataset>/reports/report_<YYYYMMDD_HHMMSS>.html 生成一張 HTML。在 WSL2 中提供直接用預設瀏覽器打開的功能。
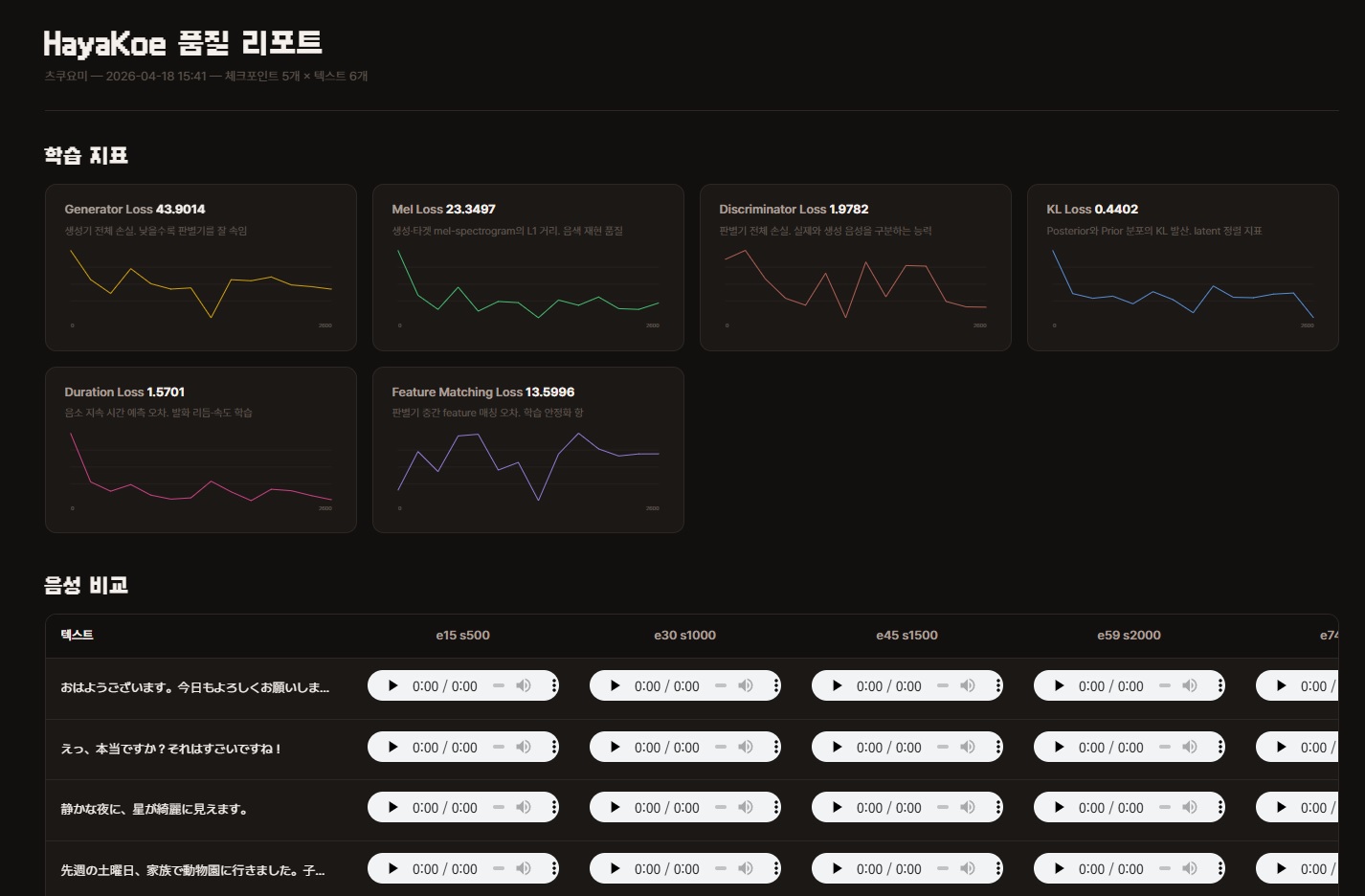
HTML 中包含兩部分內容。
- 訓練指標圖表 6 種 — loss 變化圖。可作為檢查點選擇的參考,但最終決定靠耳朵。
- 音訊比較表 — 列為評估句子,欄為檢查點。點擊各儲存格中的
<audio>播放器直接試聽。
分享很方便
WAV 以 base64 內嵌在 HTML 中,只需傳遞一個檔案所有音訊就一起跟過去了。
直接上傳到 Slack、Notion 也能無外部檔案相依地播放。
內部機制 — 檢查點取樣與生成順序
檢查點取樣
檢查點超過 8 個時會自動均勻取樣(首尾 + 中間 6 個)。即使有 10 個、20 個也不會讓頁面橫向溢出。
生成順序
- 從
<dataset>/training/和<dataset>/training/eval/收集 TensorBoard 事件檔案的純量指標。 - 逐個檢查點用
hayakoe.tts_model.TTSModel載入,合成全部評估文字後 unload。為節省 VRAM 每次只在記憶體中保留一個。 - 將指標圖表與音訊表組裝成 self-contained HTML。
如何閱讀報告
打開報告後先看到 6 張訓練指標圖表,下方是 音訊比較表。
以音訊比較表為主來看。不要只憑 loss 數字做決定 — 過擬合開始時數字會繼續下降,但耳朵聽到的結果反而會變差。
訓練指標圖表 6 種
各圖表右上角的數字是 最後一步的值。曲線本身也重要但先看終點。
- Generator Loss — 生成器總損失。越低說明越能騙過判別器
- Mel Loss — 生成與目標 mel-spectrogram 的 L1 距離。音色還原品質
- Discriminator Loss — 判別器總損失。區分真實與生成語音的能力
- KL Loss — Posterior 與 Prior 分佈的 KL 散度。latent 對齊指標
- Duration Loss — 音素持續時間預測誤差。發話節奏、速度學習
- Feature Matching Loss — 判別器中間 feature 匹配誤差。訓練穩定化項
選擇哪個檢查點
全部聽一遍,選聲音最好的。
但最後一個檢查點未必最好。資料少時越往後可能越不自然,所以中間的檢查點也務必一起聽。
如果拿不準,可以在 ④ 部署 中將候選的 2~3 個分別以不同名稱上傳,實際使用後再做選擇。
下一步
- 部署選定的檢查點:④ 部署
- 修改超參數重新訓練:② 前處理 & 訓練