① 데이터 준비
SBV2 학습에는 (wav 파일, 대응되는 텍스트) 쌍과 화자 메타데이터가 필요합니다.
녹음본만 가지고 이걸 수작업으로 만드는 건 시간이 많이 걸리는 일이라, HayaKoe는 이 과정을 브라우저 기반 GUI로 묶어 놓았습니다.
위치는 dev-tools/preprocess/ 입니다.
준비
이 단계는 영상에서 오디오를 추출하는 데 FFmpeg 를 사용합니다.
ML 의존성은 전체 흐름 페이지의 준비하기 에서 받은 uv sync 에 모두 포함되어 있지만, FFmpeg 는 시스템 패키지라서 별도 설치가 필요합니다.
FFmpeg 설치 (Ubuntu / Debian)
sudo apt update
sudo apt install ffmpeg설치가 끝나면 버전이 출력되는지 확인합니다.
ffmpeg -version실행
전처리 도구 실행
# 레포 루트에서
uv run poe preprocess브라우저로 http://localhost:8000 에 접속하면 대시보드를 볼 수 있습니다.
실행했더니 "address already in use" 오류가 뜬다면
8000번 포트를 다른 프로그램이 이미 쓰고 있다는 뜻입니다.
오류 예시는 보통 이런 모양입니다.
ERROR: [Errno 98] error while attempting to bind on address
('0.0.0.0', 8000): address already in use--port 옵션으로 비어 있는 다른 포트를 지정해서 다시 실행하면 됩니다 (예: 8123).
uv run poe preprocess --port 8123이 경우 접속 주소도 http://localhost:8123 으로 바뀝니다.
기본 워크플로우
대시보드에 처음 들어가면 다음과 같은 화면이 보입니다.
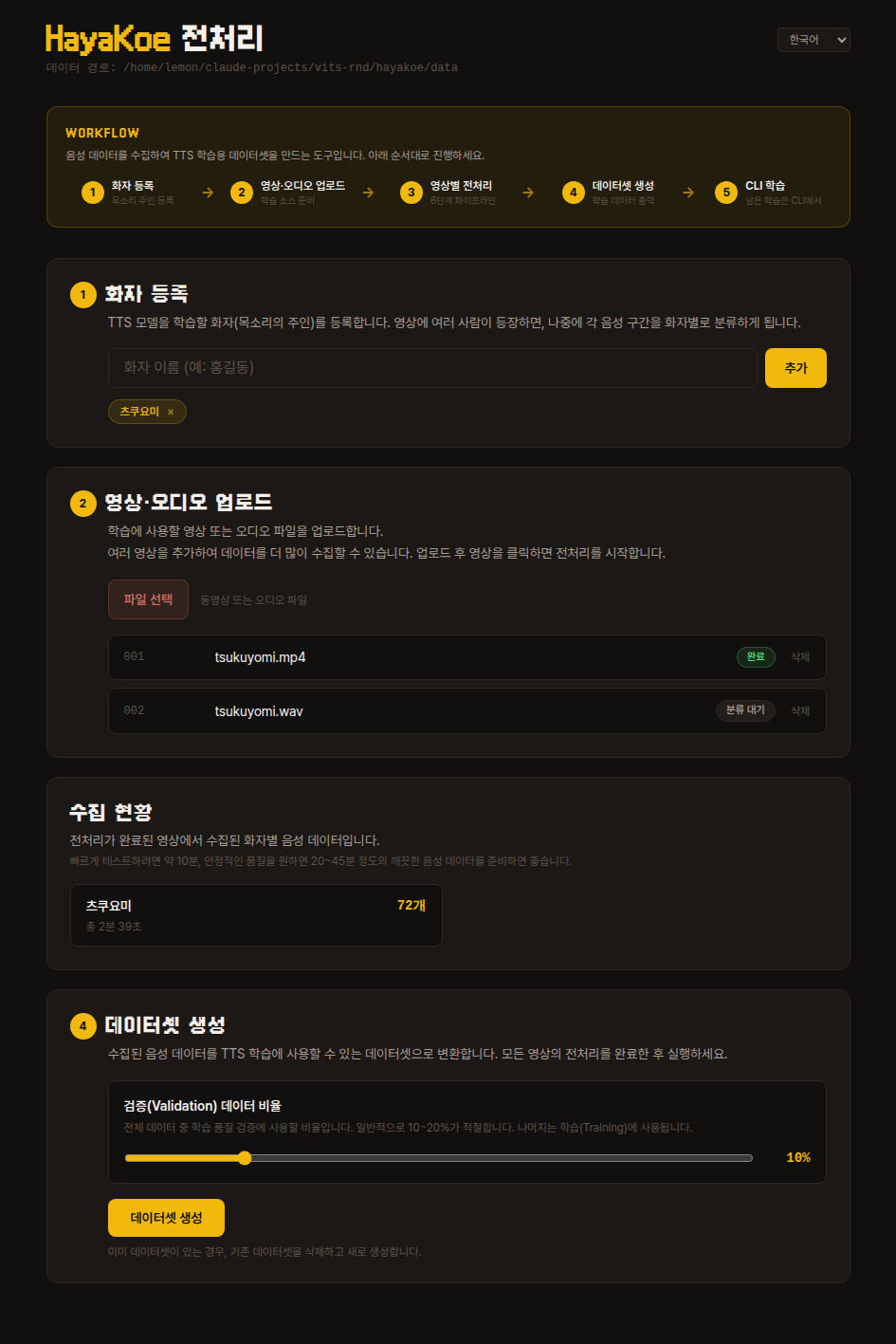
상단의 WORKFLOW 영역이 전체 흐름을 한눈에 보여주고, 그 아래로 같은 단계가 카드 형태로 펼쳐집니다.
위에서부터 순서대로 따라가면 되며, 앞 단계가 끝나야 다음 단계 카드가 활성화됩니다.
1. 화자 등록
학습 대상이 되는 화자의 이름을 등록합니다.
화자명은 본인이 알아볼 수 있는 식별자면 무엇이든 괜찮습니다 (예: tsukuyomi).
2. 영상 업로드
학습 소스가 될 영상을 업로드합니다.
영상뿐 아니라 mp3·wav·flac 같은 오디오 파일도 그대로 받을 수 있습니다 — 내부에서 FFmpeg 가 동일하게 처리합니다.
업로드가 끝나면 영상 카드가 목록에 추가되고, 카드를 클릭하면 해당 영상의 전처리 파이프라인 페이지로 이동합니다.
영상별 6단계 파이프라인
영상 상세 페이지에 들어가면 상단에 6단계 진행 바가 뜨고, 아래 NEXT STEP 카드의 버튼으로 현재 단계를 하나씩 실행합니다.
각 단계가 끝나면 자동으로 "완료" 로 바뀌고, 다음 단계가 열립니다.
중간에 끊기고 다시 들어와도 남은 단계부터 이어갑니다.
1. 추출
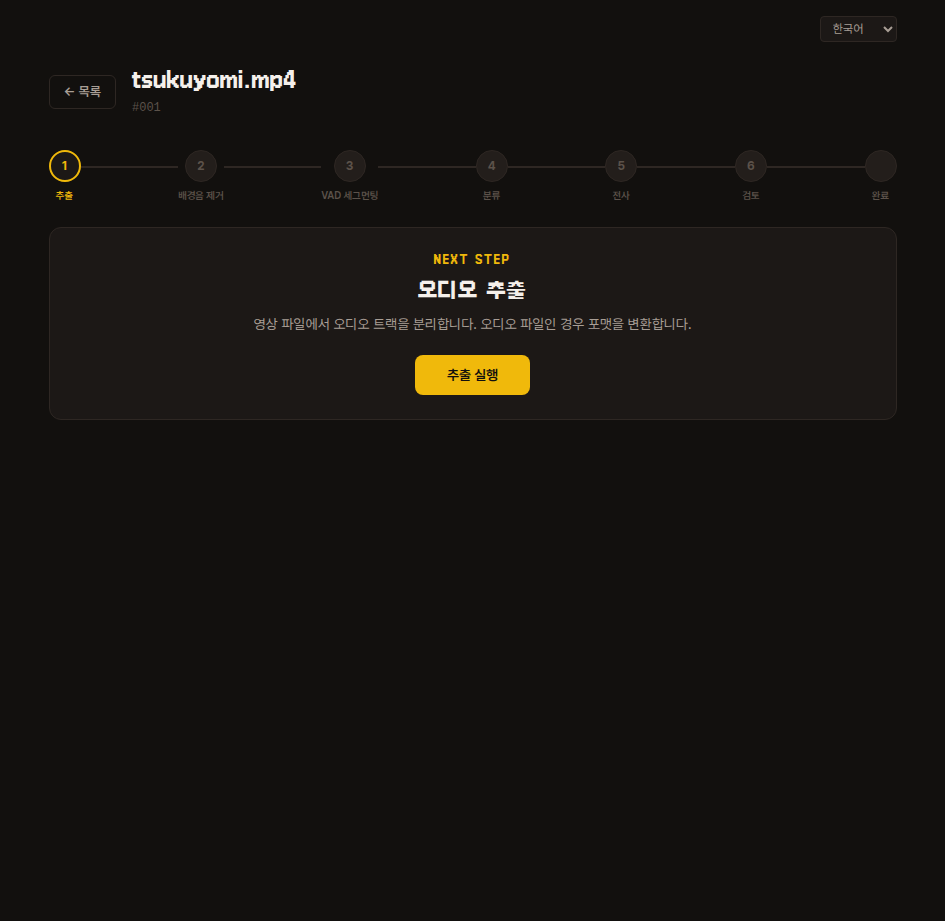
원본 데이터에서 음성만 추출하여 저장합니다.
추출이 끝나면 다음 단계로 넘어가면 됩니다.
내부 동작
내부적으로 FFmpeg 를 이용해 extracted.wav 파일을 추출합니다.
업로드한 파일이 이미 mp3·wav·flac 같은 오디오 파일이면 내용은 그대로 두고 포맷만 wav 로 변환합니다.
2. 배경음 제거
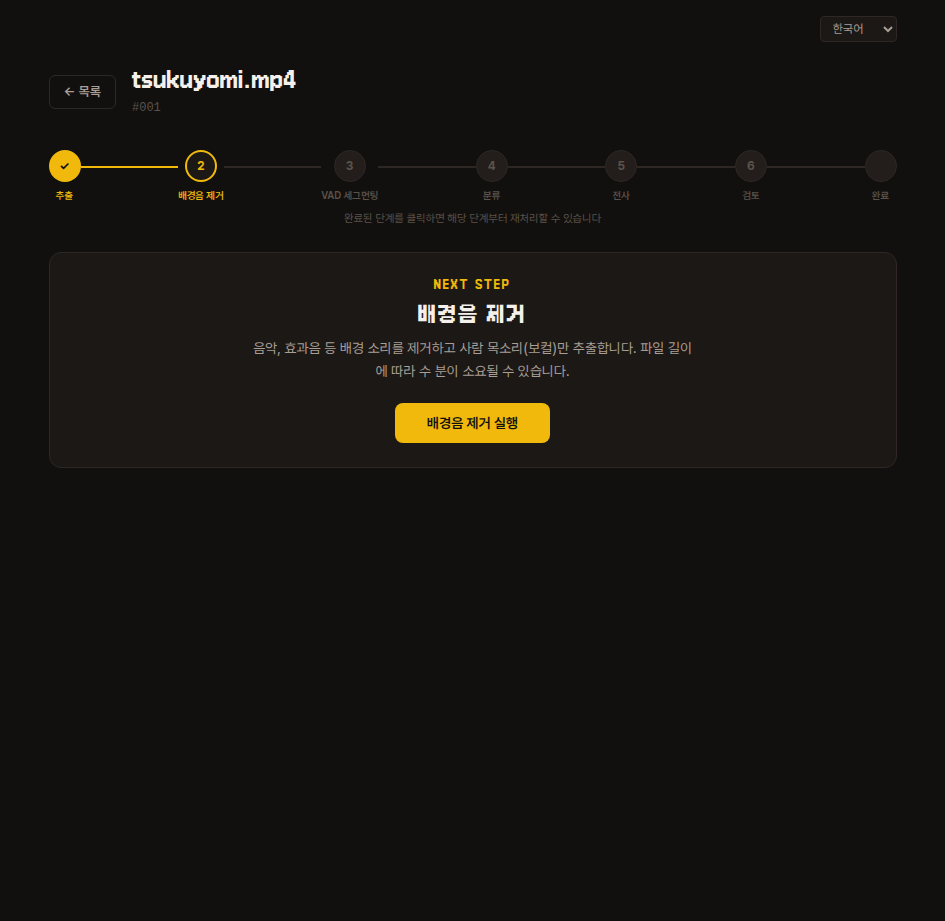
BGM·효과음 같은 배경 소리를 걷어내고, 사람 목소리만 남깁니다.
파일 길이에 비례해 수 분이 걸릴 수 있으니 기다려 주세요.
내부 동작
audio-separator 라이브러리로 보컬만 분리해 vocals.wav 로 저장합니다.
3. VAD 세그먼팅
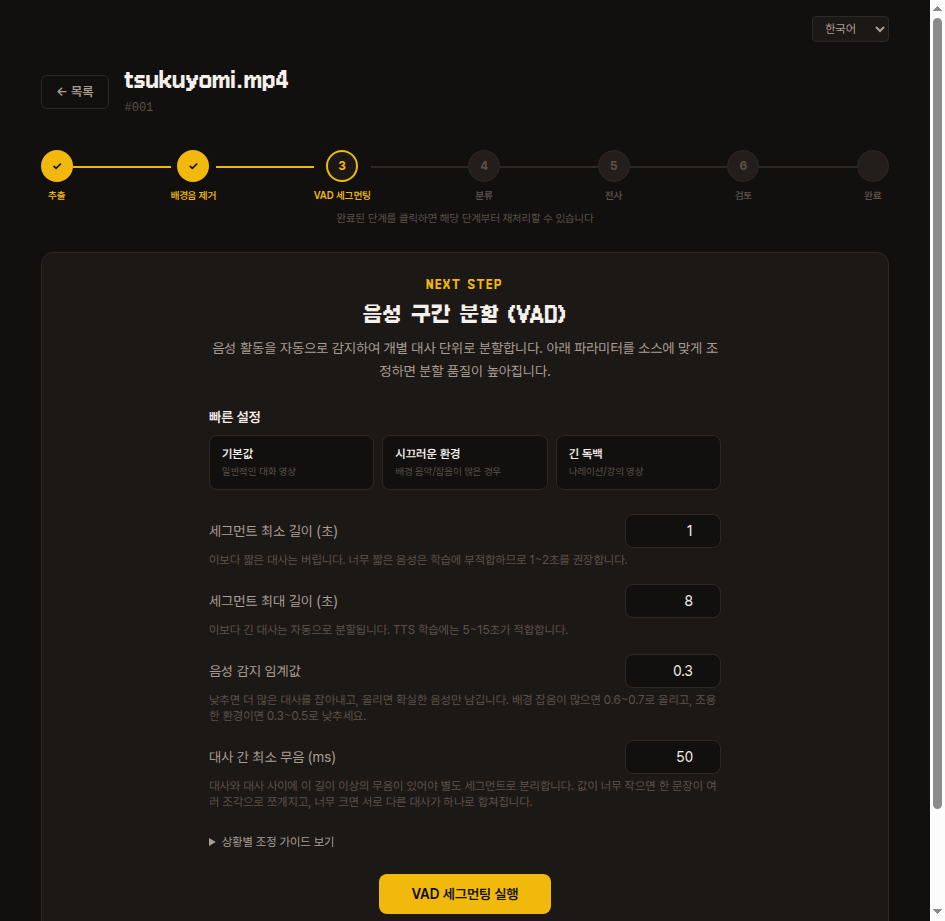
긴 녹음을 무음 구간 기준으로 짧은 문장 단위로 자릅니다.
기본값으로 먼저 실행해 보고, 분할 결과가 마음에 안 들면 네 개 파라미터를 조정해서 같은 영상에서 다시 추출할 수 있습니다.
- 세그먼트 최소 길이 (초) — 이보다 짧은 음성은 버립니다. TTS 학습에는 1-2초를 권장합니다.
- 세그먼트 최대 길이 (초) — 이보다 긴 대사는 자동으로 쪼갭니다. 5-15초가 적당합니다.
- 음성 감지 임계값 — 일단 낮은 값(0.2~0.3)으로 시작해서, 잡음이 너무 많이 잡히면 조금씩 높이는 방향을 추천합니다.
- 대사 간 최소 무음 (ms) — 일단 기본값으로 시작하세요. 여러 화자가 연속해서 말해 한 세그먼트에 섞이면 값을 줄이고, 한 대사가 너무 짧게 잘리면 값을 늘리는 방향으로 튜닝합니다.
내부 동작
Silero VAD 로 음성 활동 구간을 감지하고, 위 파라미터에 맞춰 잘라낸 결과를 vad.json 과 segments/unclassified/*.wav 로 저장합니다.
다시 실행하면 segments/unclassified/ 가 덮어씌워집니다.
4. 분류
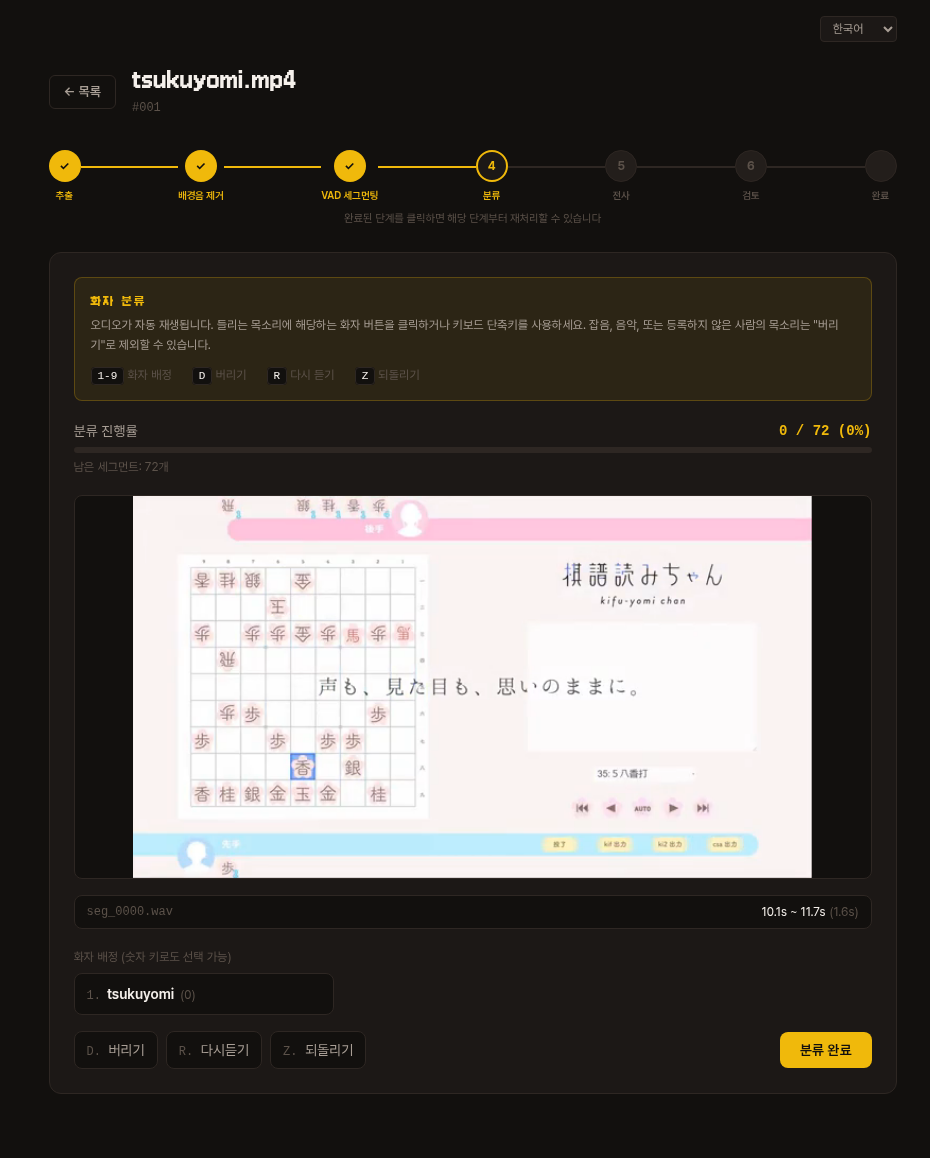
잘라낸 세그먼트가 하나씩 자동 재생됩니다.
들리는 목소리의 화자 번호 키(1-9)나 버튼을 눌러 배정하세요.
잡음·음악·등록하지 않은 사람의 목소리는 버리기(D) 로 제외합니다.
| 키 | 동작 |
|---|---|
1-9 | 해당 번호의 화자로 배정 |
D | 버리기 |
R | 다시 듣기 |
Z | 되돌리기 |
상단 진행 바에서 남은 세그먼트 개수를 확인할 수 있고, 전부 처리하면 분류 완료 버튼을 눌러 다음 단계로 넘어갑니다.
내부 동작
분류 결과는 segments/<화자>/ 구조로 저장됩니다.
5. 전사
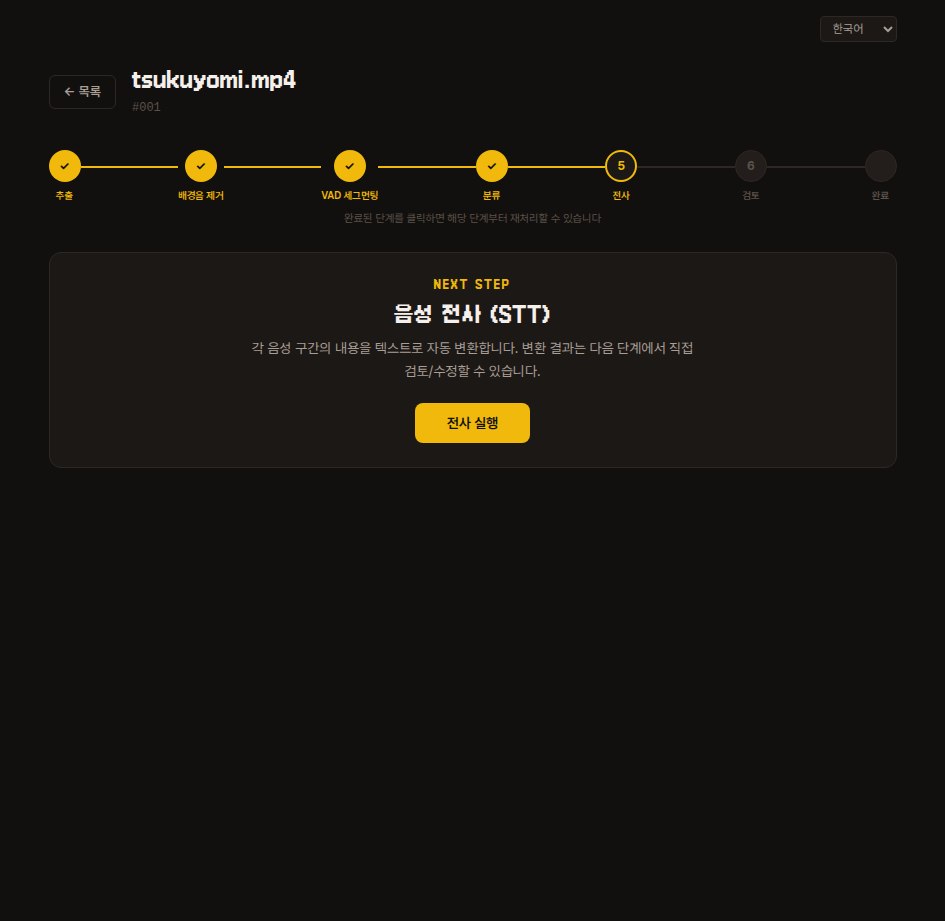
각 세그먼트의 음성을 듣고 일본어 텍스트로 자동 변환합니다.
변환 결과는 다음 단계에서 직접 수정할 수 있으니, 여기서는 실행 버튼만 누르면 됩니다.
내부 동작
Whisper 모델로 전사한 결과를 transcription.json 에 저장합니다.
6. 검토
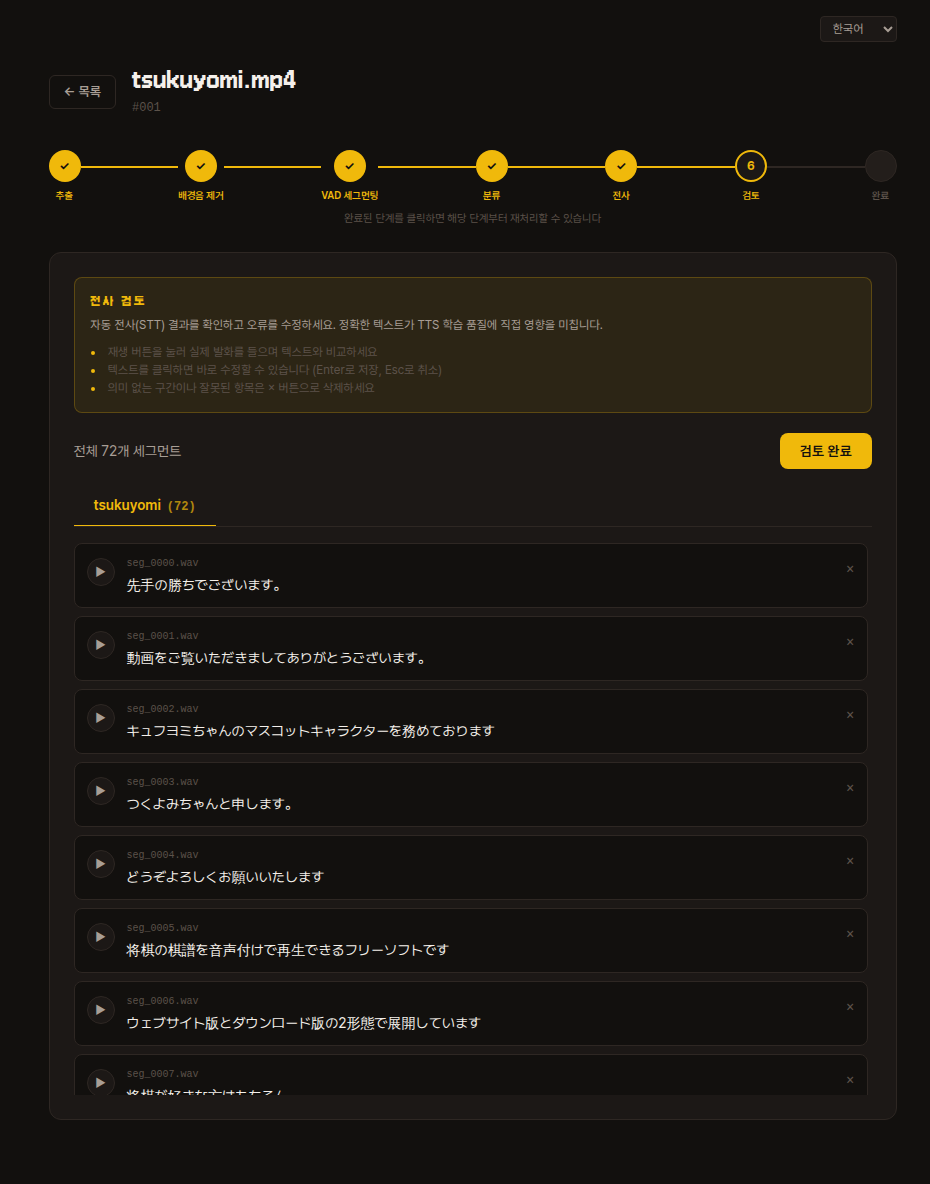
자동 전사 결과를 확인하고 오류를 수정합니다.
일본어를 모른다면 일단 넘어가도 괜찮습니다. 학습 후 품질이 낮다고 느껴지면 그때 돌아와 수정해도 좋습니다.
- 재생 버튼 을 눌러 실제 발화를 들으며 텍스트와 비교합니다.
- 텍스트를 클릭하면 바로 수정 할 수 있습니다 (
Enter로 저장,Esc로 취소). - 의미 없는 구간이나 잘못된 세그먼트는
×버튼으로 삭제합니다. - 전부 확인했으면 우측 상단 검토 완료 버튼을 눌러 다음 단계로 넘어갑니다.
내부 동작
검토 완료 마커는 review_done.json 에 저장됩니다.
여러 영상으로 데이터 모으기
한 화자에 대해 여러 개의 영상을 업로드할 수 있습니다.
영상마다 위 6단계를 반복해서 데이터를 쌓을수록 학습 품질이 올라갑니다. 처리가 끝난 데이터 기준으로 최소 10분, 30분 이상이면 대개 충분 합니다.
영상 상세 페이지 좌측 상단의 ← 목록 버튼으로 대시보드에 돌아가 다음 영상을 업로드하세요. 모든 영상의 검토까지 끝난 뒤 아래 데이터셋 생성 단계로 넘어갑니다.
데이터셋 생성
모든 영상의 검토까지 끝나면 대시보드에서 데이터셋 생성 버튼이 활성화됩니다.
val_ratio 한 값만 지정하면 학습용 데이터셋이 자동으로 만들어집니다 (기본 0.1).
val_ratio 란?
전체 데이터에서 학습에 쓰지 않고, 학습이 잘 되고 있는지 중간 점검에 쓸 비율 입니다.
학습에 사용한 데이터만으로는 모델이 그 문장만 외우고 새 문장은 어색하게 만들 수 있습니다. 그래서 일부 데이터를 일부러 빼 두고, 학습 도중 그 데이터로 합성한 결과가 자연스러운지 따로 확인합니다.
기본값 0.1 (10%) 이면 대부분의 경우 충분합니다.
생성된 데이터셋은 ② 전처리 & 학습 CLI 가 자동으로 인식하므로, 바로 다음 단계로 넘어갈 수 있습니다.
내부 동작 — 데이터셋 구조와 기본 설정
생성되는 디렉토리 구조:
data/dataset/<speaker>/
├── audio/ # 모든 영상의 세그먼트를 한곳에 복사
│ └── <video_id>_<orig_seg>.wav
├── esd.list # <abspath>|<speaker>|JP|<text>
├── train.list # esd.list의 (1 - val_ratio) 랜덤 분할 (seed 42)
├── val.list # esd.list의 val_ratio 랜덤 분할
└── sbv2_data/
└── config.json # SBV2 JP-Extra 기본 설정config.json 의 주요 기본값:
model_name: "hayakoe_<speaker>"version: "2.7.0-JP-Extra"train.epochs: 500,batch_size: 2,learning_rate: 0.0001train.eval_interval: 1000,log_interval: 200data.sampling_rate: 44100,num_styles: 7style2id: Neutral / Happy / Sad / Angry / Fear / Surprise / Disgust
이 값들은 ② 전처리 & 학습 단계의 학습 설정 편집 에서 바꿀 수 있습니다.
내부 동작 — data/ 루트 전체 구조
--data-dir ./data 기준 최종 구조:
data/
├── speakers.json # 등록된 화자 목록
├── videos/ # 영상별 전처리 작업 공간
│ └── <001, 002, ...>/
│ ├── source.<ext>
│ ├── meta.json
│ ├── extracted.wav
│ ├── vocals.wav
│ ├── vad.json
│ ├── segments/
│ ├── classification.json
│ ├── transcription.json
│ └── review_done.json
└── dataset/ # 학습 단계의 입력
└── <speaker>/ # ← CLI가 이 경로를 자동 인식CLI 는 data/dataset/ 아래에서 esd.list 또는 sbv2_data/esd.list 를 가진 디렉토리를 자동으로 리스트업합니다.
다음 단계
- 데이터셋을 학습으로 넘기기: ② 전처리 & 학습