① 資料準備
SBV2 訓練需要 (wav 檔案, 對應文字) 對與話者中繼資料。
僅憑錄音手動製作這些非常耗時,HayaKoe 將此過程封裝為基於瀏覽器的 GUI。
位置在 dev-tools/preprocess/。
準備
此步驟使用 FFmpeg 從影片中擷取音訊。
ML 相依套件已包含在 全流程頁面的準備工作 中的 uv sync 裡,但 FFmpeg 是系統套件,需要單獨安裝。
安裝 FFmpeg (Ubuntu / Debian)
sudo apt update
sudo apt install ffmpeg安裝完成後確認版本能正常輸出。
ffmpeg -version執行
啟動前處理工具
# 在儲存庫根目錄
uv run poe preprocess在瀏覽器中存取 http://localhost:8000 即可看到儀表板。
執行後出現 "address already in use" 錯誤
表示 8000 連接埠已被其他程式佔用。
錯誤訊息通常如下所示。
ERROR: [Errno 98] error while attempting to bind on address
('0.0.0.0', 8000): address already in use使用 --port 選項指定其他閒置連接埠重新執行即可(例如:8123)。
uv run poe preprocess --port 8123此時存取網址也變為 http://localhost:8123。
基本工作流程
首次進入儀表板時會看到如下介面。
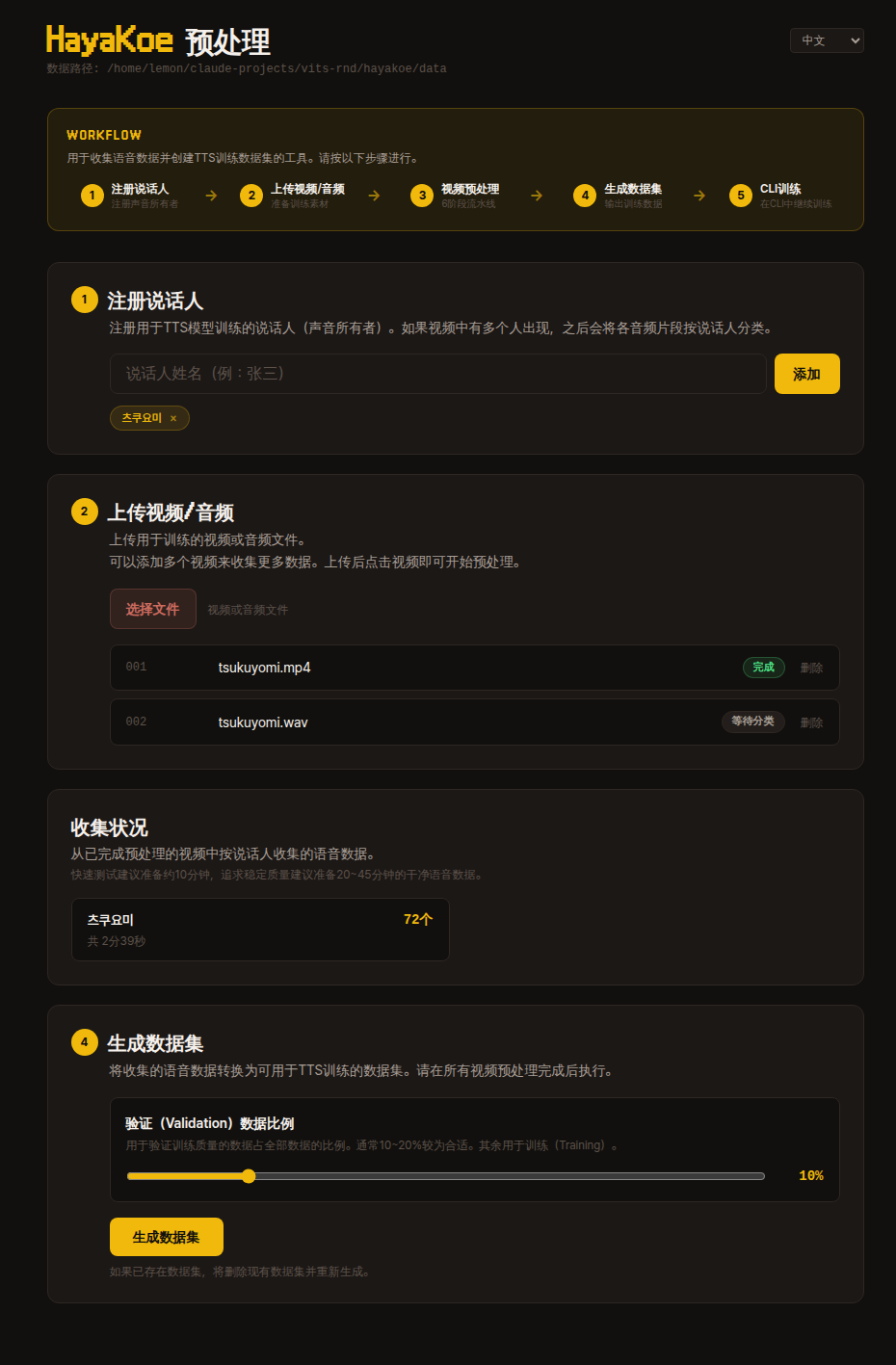
頂部的 WORKFLOW 區域展示全流程概覽,下方以卡片形式展開相同的步驟。
從上到下依序操作即可,前一步驟完成後下一步驟的卡片才會啟用。
1. 註冊話者
註冊訓練目標話者的名稱。
話者名稱只要是您能識別的識別碼就行(例如:tsukuyomi)。
2. 上傳影片
上傳作為訓練素材的影片。
不僅是影片,mp3·wav·flac 等音訊檔案也可以直接上傳 — 內部由 FFmpeg 統一處理。
上傳完成後影片卡片會新增到清單中,點擊卡片即可進入該影片的前處理流水線頁面。
每個影片的 6 步流水線
進入影片詳情頁面後,頂部顯示 6 步進度條,透過下方 NEXT STEP 卡片的按鈕逐步執行目前步驟。
每步完成後會自動變為「已完成」,下一步隨即開啟。
中途中斷再次進入時會從剩餘步驟繼續。
1. 擷取
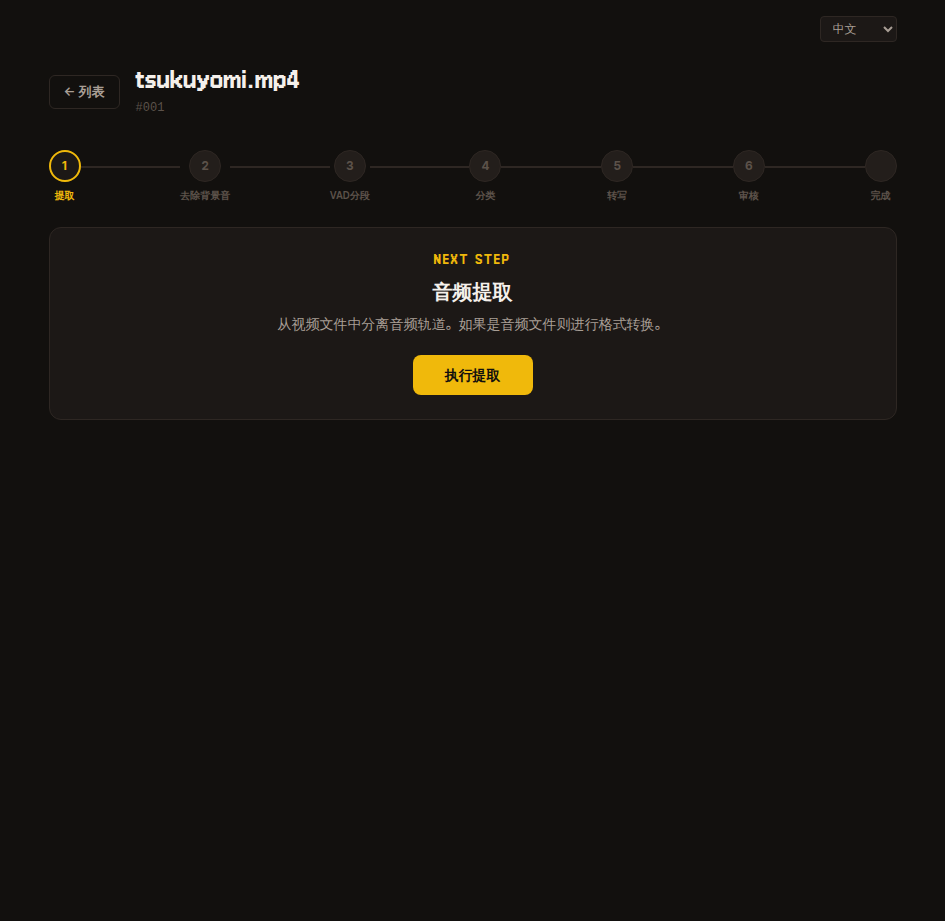
從原始資料中擷取音訊並儲存。
擷取完成後繼續下一步即可。
內部機制
內部使用 FFmpeg 擷取 extracted.wav 檔案。
如果上傳的檔案已是 mp3·wav·flac 等音訊檔案,內容保持不變僅轉換格式為 wav。
2. 背景音去除
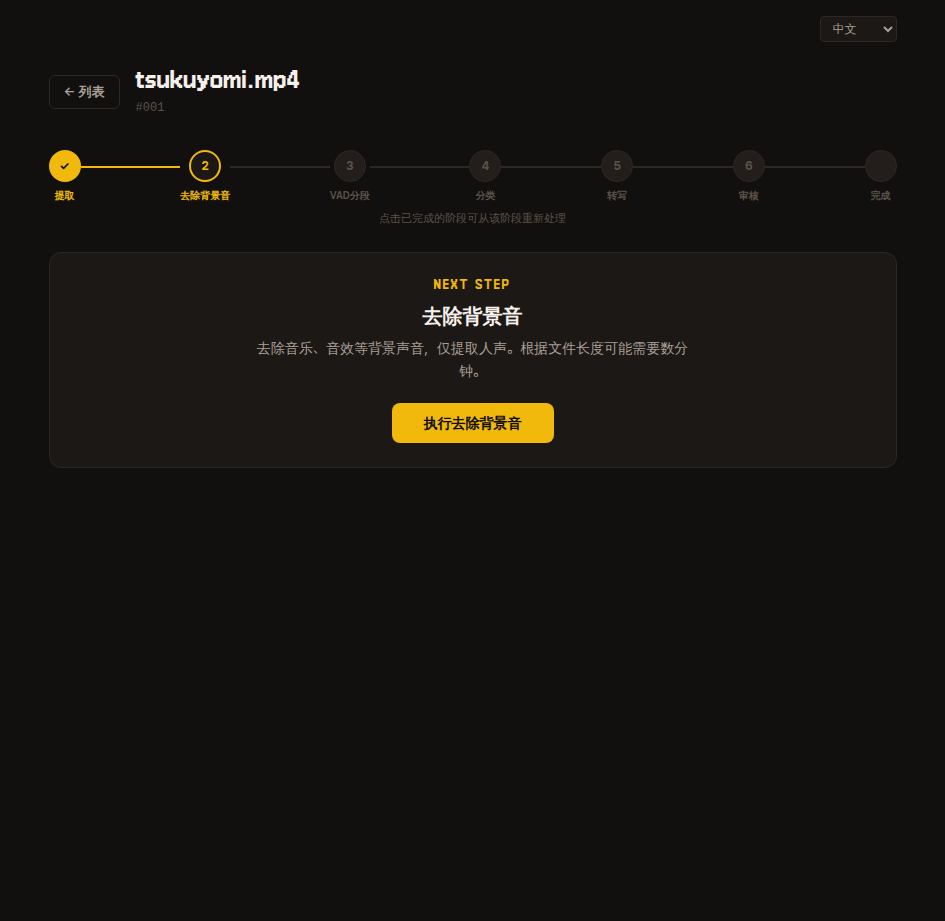
去除 BGM·音效等背景聲音,僅保留人聲。
所需時間與檔案長度成正比,可能需要數分鐘,請耐心等待。
內部機制
使用 audio-separator 函式庫分離人聲並儲存為 vocals.wav。
3. VAD 分割
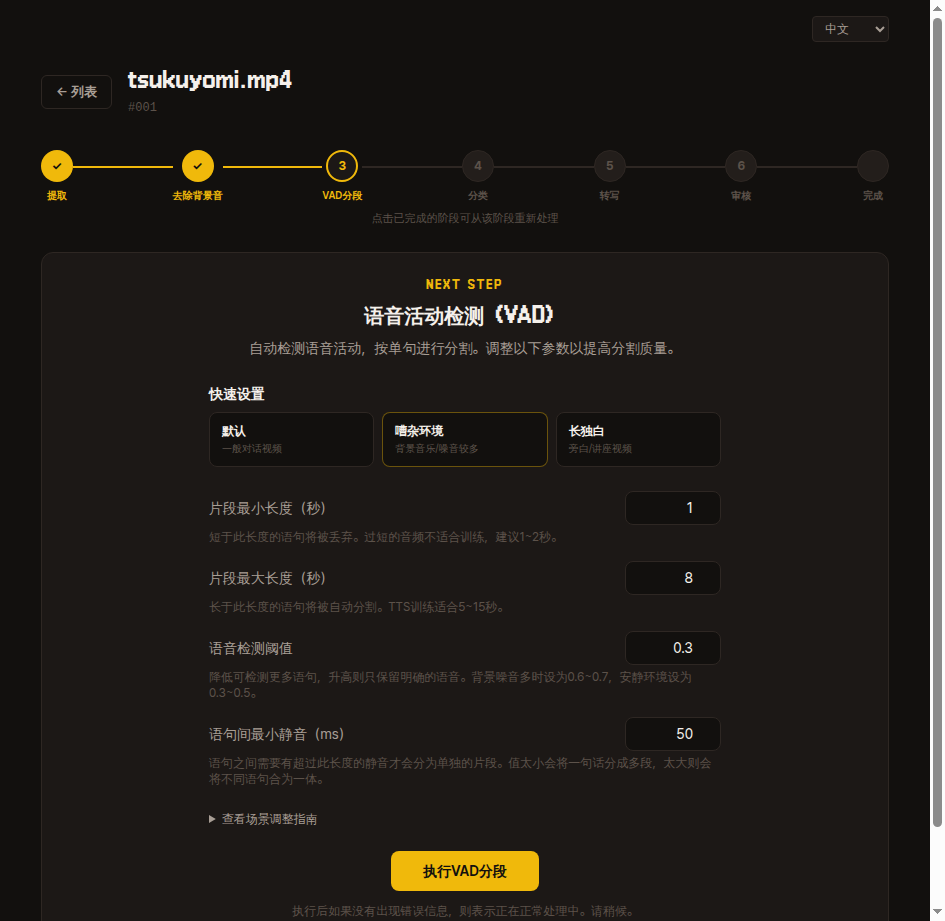
將長錄音按靜音區間分割為短句。
先用預設值執行,如果分割結果不滿意,可以調整四個參數後從同一影片重新擷取。
- 片段最短時長(秒) — 短於此值的語音會被丟棄。TTS 訓練建議 1-2 秒。
- 片段最長時長(秒) — 超過此值的台詞會被自動拆分。5-15 秒比較合適。
- 語音偵測閾值 — 建議從較低值(0.2~0.3)開始,如果雜訊太多則逐漸提高。
- 台詞間最短靜音(ms) — 先用預設值開始。如果多個話者連續說話導致一個片段中混雜多人聲音則減小該值,如果單個台詞被切得太短則增大該值。
內部機制
使用 Silero VAD 偵測語音活動區間,按上述參數分割後將結果儲存為 vad.json 與 segments/unclassified/*.wav。
重新執行時 segments/unclassified/ 會被覆寫。
4. 分類
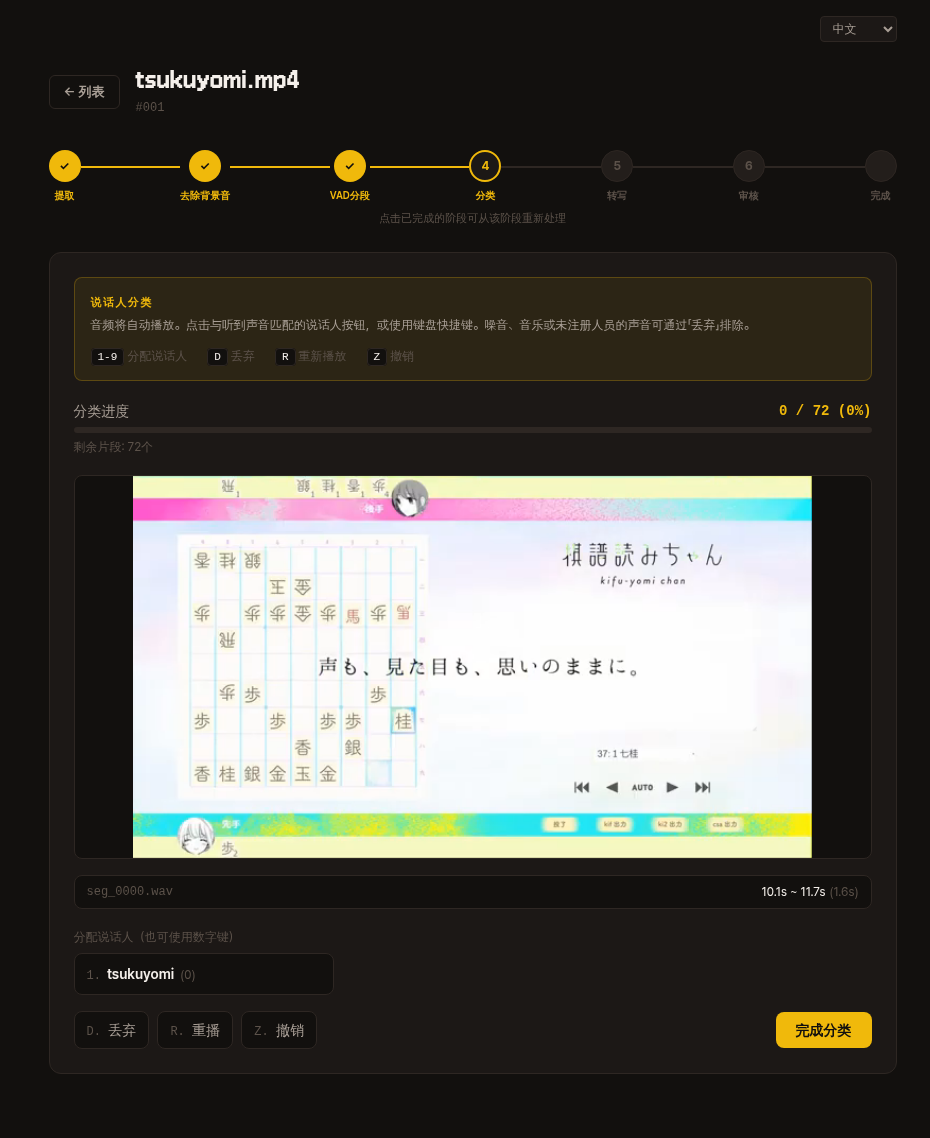
分割出的片段會逐個自動播放。
按下聽到的聲音對應的話者編號鍵(1-9)或按鈕進行指派。
雜訊·音樂·未註冊人的聲音用 丟棄(D) 排除。
| 鍵 | 操作 |
|---|---|
1-9 | 指派給對應編號的話者 |
D | 丟棄 |
R | 重聽 |
Z | 復原 |
在頂部進度條可以確認剩餘片段數量,全部處理完後點擊 分類完成 按鈕進入下一步。
內部機制
分類結果儲存為 segments/<話者>/ 目錄結構。
5. 轉錄
聆聽各片段的語音並自動轉換為日語文字。
轉換結果可以在下一步中手動修正,這裡只需點擊執行按鈕。
內部機制
使用 Whisper 模型轉錄的結果儲存在 transcription.json 中。
6. 審核
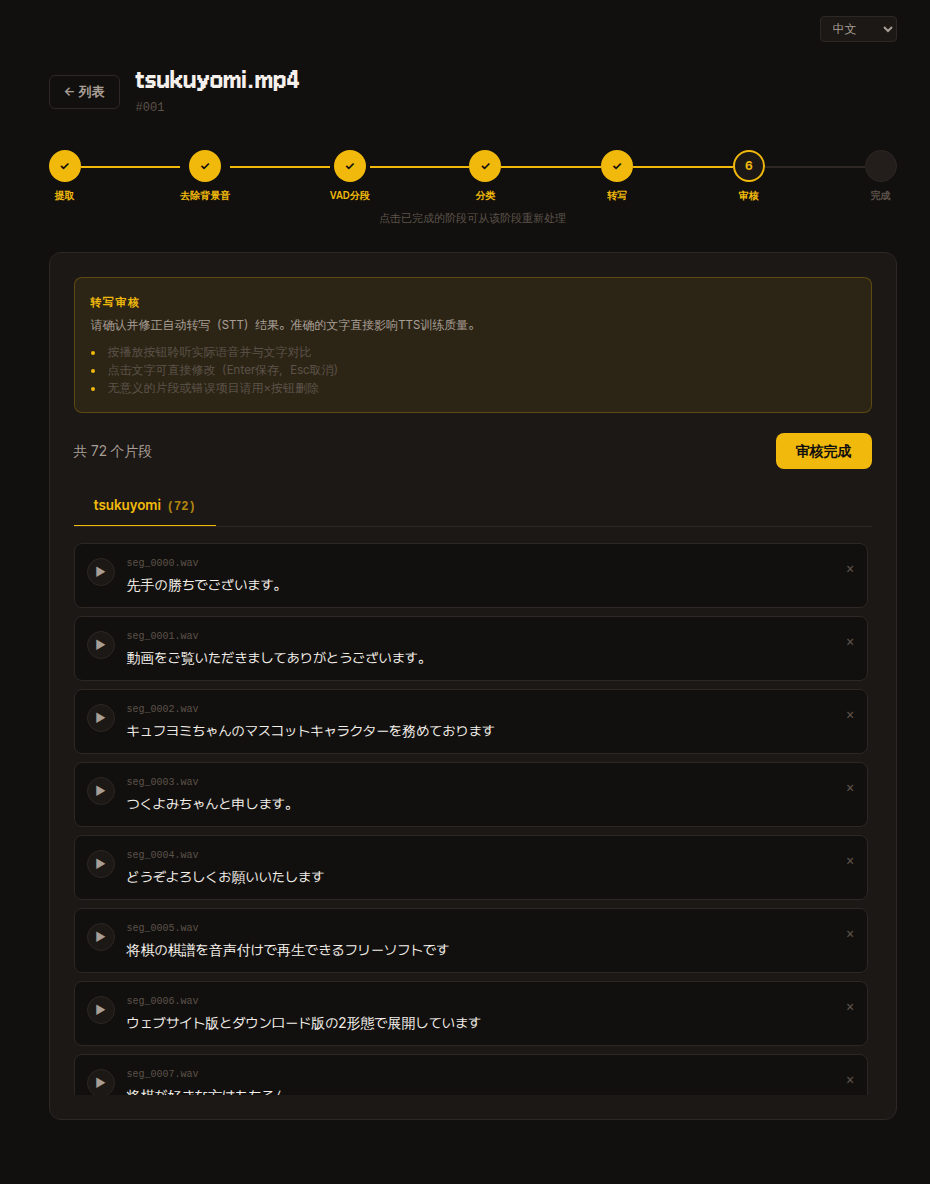
確認並修正自動轉錄結果。
如果不懂日語可以先跳過。訓練後如果感覺品質不佳,可以返回修正。
- 點擊 播放按鈕 聆聽實際發音並與文字對比。
- 點擊文字即可直接修改(
Enter儲存,Esc取消)。 - 無意義的區間或錯誤的片段用
×按鈕刪除。 - 全部確認後點擊右上角 審核完成 按鈕進入下一步。
內部機制
審核完成標記儲存在 review_done.json 中。
用多個影片收集資料
可以為一個話者上傳多個影片。
每個影片重複上述 6 步累積資料越多訓練品質越高。按處理完的資料計算,最少 10 分鐘,30 分鐘以上通常足夠。
在影片詳情頁面左上角的 ← 清單 按鈕返回儀表板上傳下一個影片。所有影片審核完成後進入下方資料集生成步驟。
資料集生成
所有影片審核完成後,儀表板上的 資料集生成 按鈕會被啟用。
只需指定 val_ratio 一個值即可自動生成訓練資料集(預設 0.1)。
什麼是 val_ratio?
從全部資料中 不用於訓練而是用於中間檢驗訓練效果的比例。
僅用訓練資料的話模型可能只是背下了那些句子,對新句子合成效果不佳。因此刻意留出一部分資料,訓練過程中用這些資料合成結果檢查是否自然。
預設值 0.1(10%)在大多數情況下足夠。
生成的資料集會被 ② 前處理 & 訓練 CLI 自動識別,可以直接進入下一步。
內部機制 — 資料集結構與預設設定
生成的目錄結構:
data/dataset/<speaker>/
├── audio/ # 所有影片的片段複製到同一位置
│ └── <video_id>_<orig_seg>.wav
├── esd.list # <abspath>|<speaker>|JP|<text>
├── train.list # esd.list 的 (1 - val_ratio) 隨機分割 (seed 42)
├── val.list # esd.list 的 val_ratio 隨機分割
└── sbv2_data/
└── config.json # SBV2 JP-Extra 預設設定config.json 的主要預設值:
model_name: "hayakoe_<speaker>"version: "2.7.0-JP-Extra"train.epochs: 500,batch_size: 2,learning_rate: 0.0001train.eval_interval: 1000,log_interval: 200data.sampling_rate: 44100,num_styles: 7style2id: Neutral / Happy / Sad / Angry / Fear / Surprise / Disgust
這些值可以在 ② 前處理 & 訓練步驟的 訓練設定編輯 中修改。
內部機制 — data/ 根目錄完整結構
基於 --data-dir ./data 的最終結構:
data/
├── speakers.json # 已註冊的話者清單
├── videos/ # 各影片的前處理工作空間
│ └── <001, 002, ...>/
│ ├── source.<ext>
│ ├── meta.json
│ ├── extracted.wav
│ ├── vocals.wav
│ ├── vad.json
│ ├── segments/
│ ├── classification.json
│ ├── transcription.json
│ └── review_done.json
└── dataset/ # 訓練步驟的輸入
└── <speaker>/ # ← CLI 自動識別此路徑CLI 會自動列出 data/dataset/ 下包含 esd.list 或 sbv2_data/esd.list 的目錄。
下一步
- 將資料集送入訓練:② 前處理 & 訓練